はじめに
polkaは、タグとリンクでつながる新しい分散型Webプロトコルです。「検証可能なWeb 1.0」をコンセプトに、個人サイトの自由さと、分散型技術による信頼性を両立させます。
開発の背景:既存Webの課題
現代のWebでは、サービス管理者がデータを保持し、APIを通じて提供しています。しかし、この構造には以下の課題があります。
中央集権的なコントロール
運営企業の判断により、アカウントがBANされたり、投稿へのアクセスが遮断されたりします。自分のデータであっても、完全にはコントロールできません。
プラットフォーム依存
API制限やサービス終了により、これまでの活動やコミュニティが失われるリスクがあります。プラットフォームに依存している限り、この不安は消えません。
polkaの3要素
polkaは以下の3つの柱によって、「検証可能なWeb 1.0」を実現します。
1. データとサービスの分離
ユーザー自身がサーバーでデータを公開し、アプリがそこに直接アクセスします。データはあなたのものです。
2. 電子署名による検証可能性
すべてのデータは暗号学的に署名され、改ざんを検出できます。誰が書いたか、改ざんされていないかが、数学的に保証されます。
3. 賢いリンク
タグを用いたグラフ構造により、中央管理者なしでコミュニティが自然発生します。興味のあるタグをフォローするだけで、つながりが生まれます。
次に読むべきページ
polkaをより深く理解するために、以下のページを読むことをお勧めします。
polkaがなぜこのような設計になっているのか、その思想と背景を説明します。
polkaのアーキテクチャと、各コンポーネントがどのように連携するかを説明します。
polkaの世界観
polkaは「検証可能なWeb 1.0」という新しいアプローチで、分散型Webの課題に取り組んでいます。このページでは、polkaが生まれた背景と、その設計思想を説明します。
検証可能なWeb 1.0とは
個人サイトは完全に自分のものです。自分のドメイン、自分のサーバー、自分のHTMLファイル。誰にも削除されることなく、自由に表現できます。 polkaは、セルフホストの自由さに、現代の暗号技術による検証可能性を組み合わせます。
個人サイトの自律性
ユーザーは自分のドメインでデータをホスティングします。サービス提供者に依存せず、アカウントBANの心配もありません。
暗号学的な信頼性
すべてのデータは電子署名されています。改ざんされたデータは暗号学的に検証不可能となり、自動的に排除されます。
この2つの両立こそが、polkaの目指す世界です。
大規模インフラへの非依存
polkaの最も重要なコンセプトの1つが、「ソーシャルグラフを大規模インフラに依存させない」ことです。
ソーシャルグラフはユーザーのもの
従来の分散型SNSでは、ソーシャルグラフは大規模なリレーやインデクサーに保存されます。これらのインフラが停止すれば、つながりそのものが失われます。
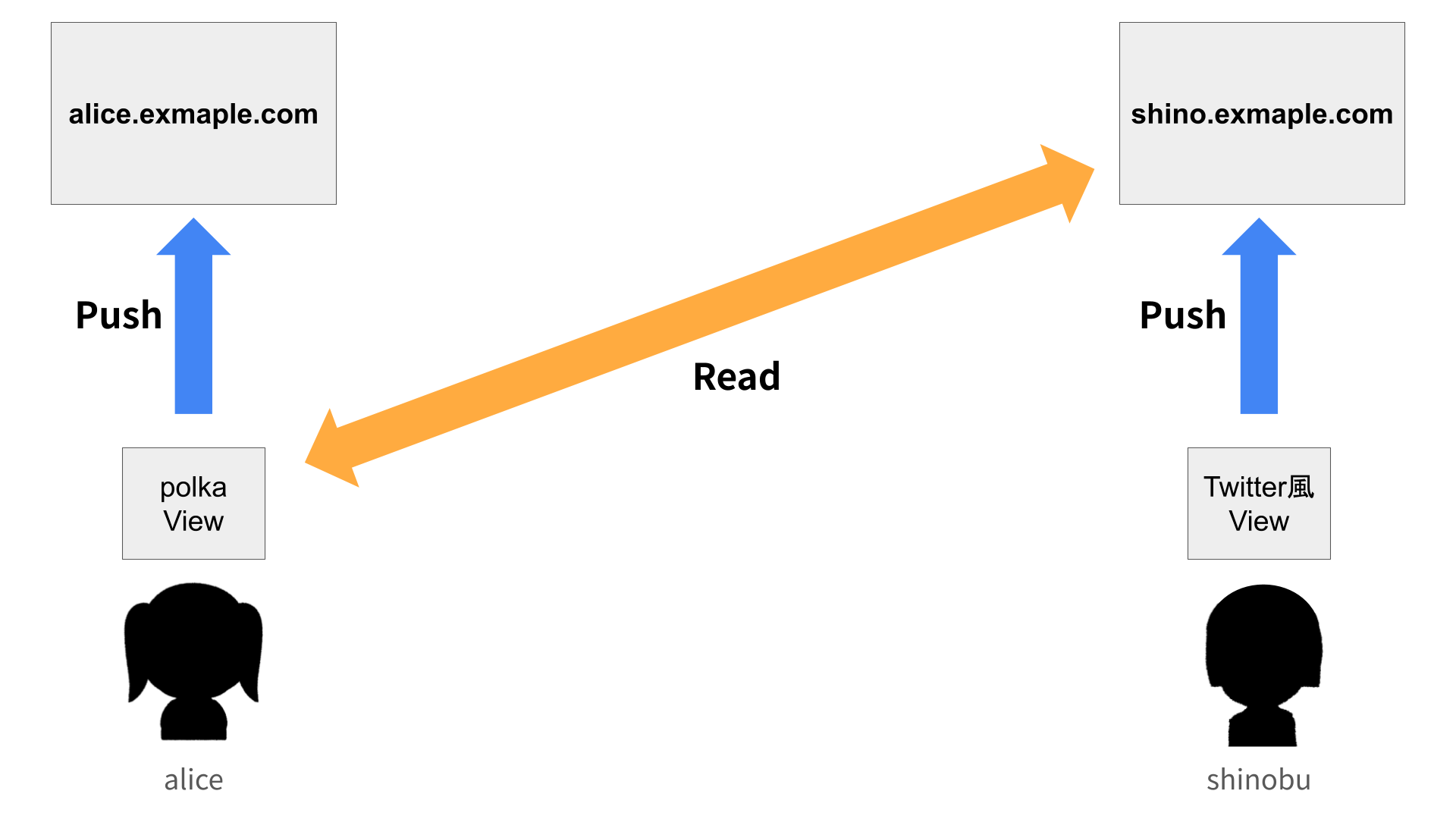
polkaでは、ソーシャルグラフは各ユーザーのサーバーに保存されます。あなたがフォローしているタグのリストは、あなたのローカルに保存され、相手のHTTPSサーバーから直接データを取得します。
発見と保持の分離
Nostrリレーは「発見」のためだけに使われます。一度つながりを見つけたら、そのつながりはローカルに保存され、以降は直接HTTPSでアクセスします。
これは、現実世界で誰かと知り合う過程に似ています。最初はイベントやSNSで出会いますが、一度つながれば、そのイベントが消えても関係は続きます。
トピック中心のスモールワールド
polkaのもう1つの核心は、タグを中心とした緩やかなつながりです。
タグによる自然なコミュニティ
polkaでは、ユーザーではなく「タグ」をフォローします。たとえば、Aliceさんのこけしに関する投稿だけに興味があるなら、alice.example.com/japan/kokeshi をフォローします。
タグは階層構造を持ちます。alice.example.com/japan をフォローすれば、その配下の kokeshi、shinobu などすべてのサブタグが取得されます。
これにより、細かい興味に絞ることも、広いトピック全体を購読することも可能になります。
中央管理者のいない自律性
タグには中央的な管理者がいません。たとえば kokeshi というタグは、それを使いたい人が自由に使います。同じタグを使う人々が自然につながり、コミュニティが形成されます。
スモールワールドの形成
polkaは大規模なグローバルネットワークを目指していません。むしろ、小さな興味のクラスターが緩やかにつながり合う「スモールワールド」を志向しています。
すべてのユーザーがすべてのユーザーを発見する必要はありません。自分の興味のあるタグに関わる人々とつながれば、それで十分です。
この設計により、大規模なインフラなしでも、意味のあるつながりが育まれます。
システム全体像
polkaは複数の技術を組み合わせて、分散型の検証可能なWebを実現しています。このページでは、システムの構成要素と、それらがどのように連携するかを説明します。
システム構成
polkaは、以下のレイヤーから構成されています。
データ層: ATProtocol Repo データの構造化と検証を担当します。Merkle Search Treeにより、すべてのデータをまとめて検証できます。
ストレージ層: Git + 静的ファイルホスティング データの永続化と配信を担当します。Gitでバージョン管理し、静的ファイルとしてHTTPSで配信します。
アイデンティティ層: did:web + HTTPS/DNS ドメインと公開鍵の紐付けを担当します。既存のHTTPS/DNSインフラを信頼の基盤とします。
発見層: Nostr + Bloom Filter ユーザーの発見を担当します。Nostrリレーに自分の存在を広告し、興味のあるタグを持つユーザーを見つけます。
検証層: 電子署名 (Secp256k1) データの真正性を担当します。すべてのデータは署名され、検証されます。
これらのレイヤーが協調して動作することで、polkaの分散型Webが実現されます。
データ層: ATProtocol Repo
polkaのデータは、ATProtocolのリポジトリ形式で管理されます。
Merkle Search Tree
Merkle Search Tree(MST)は、複数のデータをソート済みの木構造で管理し、ルートハッシュで全体を検証できる仕組みです。
polkaでは、タグの階層構造、投稿、プロフィールなど、すべてのデータがMSTに格納されます。MSTのルートハッシュに署名することで、データ全体の整合性が保証されます。
BlockStore
実際のデータは、CIDをキーとしたブロックストアに保存されます。各ブロックはCBOR形式でエンコードされ、そのハッシュがCIDとなります。
クライアントは必要なブロックだけを取得できるため、リポジトリ全体をダウンロードする必要はありません。
Commitオブジェクト
Commitオブジェクトは、MSTのルート、DID、署名を含みます。このCommitがリポジトリ全体のスナップショットとなり、検証の起点となります。
ストレージ層: Git + 静的ファイルホスティング
polkaのデータ配信は、極めてシンプルです。静的ファイルをHTTPSで配信するだけです。
ローカルでのデータ管理
ユーザーのローカルで、データはCAR形式のファイルとして保存されます。このファイルには、すべてのブロックが含まれています。
ビルドプロセス
データを公開するとき、CARファイルから個別のブロックファイルが生成されます。各ブロックは {CID} という名前のファイルとして保存され、ルートCIDは ROOT というファイルに書き込まれます。
Gitによるバージョン管理
生成されたブロックファイルは、Gitリポジトリにコミットされます。これにより、データの変更履歴が記録され、必要に応じて過去の状態に戻すことができます。
静的ホスティング
Gitリポジトリは、GitHub Pages、Netlify、Caddy、Nginxなど、任意の静的ファイルホスティングサービスで公開されます。CORSヘッダーさえ適切に設定されていれば、どのホスティングでも動作します。
クライアントは、https://example.com/polka/ROOT でルートCIDを取得し、https://example.com/polka/{cid} で各ブロックを取得します。
アイデンティティ層: did:web
polkaは、ドメイン名と公開鍵の紐付けに did:web を使用します。
DID Document
ユーザーは、自分のドメインの .well-known/did.json に DID Document を配置します。このドキュメントには、公開鍵とpolkaリポジトリのサービスエンドポイントが記載されています。
複数鍵の対応
DID Documentには複数の公開鍵を登録できます。これにより、鍵のローテーションや、複数デバイスでの運用が可能になります。
クライアントは、いずれかの鍵で署名が検証できれば、そのデータを正当なものとして受け入れます。
発見層: Nostr
polkaは、ユーザー発見にNostrを使用します。
Kind 25565: タグ広告
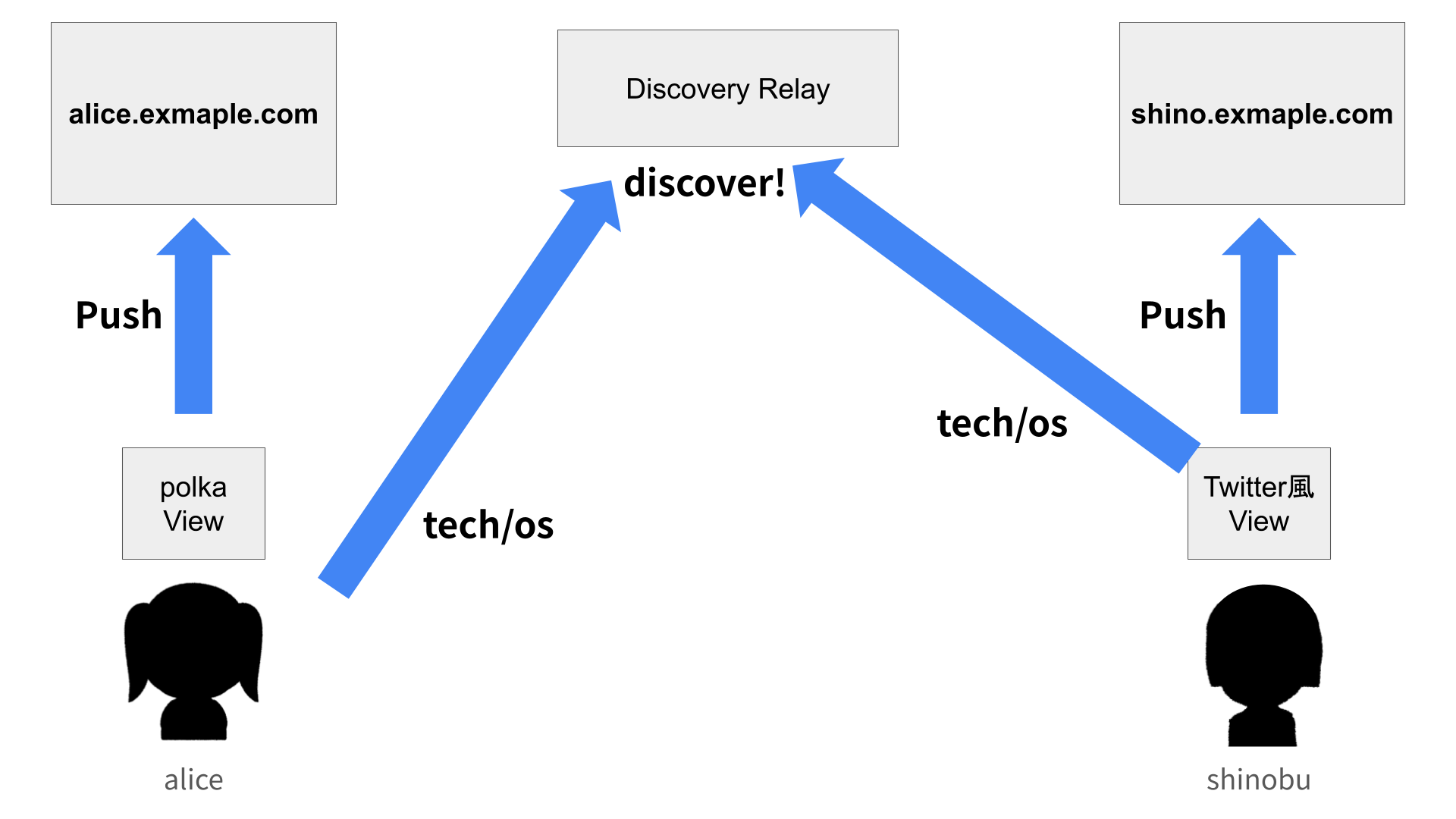
ユーザーは、自分が使っているタグを Bloom Filter にエンコードし、Nostr リレーに広告します。イベントの kind は 25565 で、content に DID と Bloom Filter が含まれます。
Bloom Filterによるマッチング
Bloom Filterは確率的データ構造です。クライアントは受信したBloom Filterに対して、興味のあるタグが含まれているかをチェックします。
偽陽性の可能性はありますが、偽陰性はありません。マッチした場合、クライアントは相手のDIDを解決し、実際のデータを取得して確認します。
Bloom Filterの偽陽性は、自分と関係のないトピックのユーザーも発見できる、スパイスとして位置付けています。
発見後のフォロー
一度マッチしたユーザーを見つけたら、そのユーザーのタグノードをローカルに保存します。以降は、Nostrリレーを経由せず、HTTPS経由で直接データを取得します。
Nostrは「ブートストラップ」の役割であり、継続的なデータ取得には使用されません。
検証層: 電子署名
polkaのすべてのデータは、Secp256k1電子署名により保護されています。
署名の流れ
- ユーザーがデータを作成・更新する
- MSTが再構築され、新しいルートハッシュが生成される
- Commitオブジェクトが作成され、秘密鍵で署名される
- 署名されたCommitとブロックが保存される
検証の流れ
- クライアントがROOTからルートCIDを取得
- ルートCIDでCommitブロックを取得
- did:webからユーザーの公開鍵を取得
- Commitの署名を検証
- 署名が正しければ、MSTを走査してデータを取得
改ざんされたデータは署名検証で失敗し、CIDが一致しないブロックは拒否されます。
なぜATProtocolとNostrなのか
ATProtocol: 検証可能なデータベースとして
polkaでは、ユーザーごとにタグの階層構造を持ちます。たとえば、japan/kokeshi や anime/ikizulive/polka のような階層です。これらのタグは相互にリンクし合い、グラフ構造を形成します。
このグラフ全体を検証可能にする必要がありました。1つのタグだけでなく、グラフ全体の整合性を効率よく証明する仕組みが必要だったのです。
ATProtocolのデータ構造、特にMerkle Search Treeは、まさにこの用途に最適でした。MSTは複数のデータをまとめてハッシュ化し、そのルートハッシュに署名することで、グラフ全体の正しさを効率的に証明できます。
polkaはATProtocolを、Blueskyのような大規模SNSではなく、単純な「検証可能なデータベース」として使っています。
Nostr: ブートストラップとして
分散型システムには、「他のユーザーをどうやって見つけるか」という根本的な課題があります。
polkaはこの問題に対して、Nostrの既存インフラを活用しています。ユーザーはNostrリレーに自分の存在を広告し、興味のあるタグを持つ他のユーザーを発見します。
重要なのは、Nostrは一時的な発見の手段でしかない、という点です。一度つながりを見つければ、その後のデータ取得はHTTPS経由で直接行われます。リレーがダウンしても、既存のフォロー関係は影響を受けません。
この設計により、大規模なリレーインフラに依存せず、最小限の調整だけでネットワークが機能します。
データモデル
polkaは、ATProtocolのリポジトリ形式を採用しています。このページでは、polkaで使用されるデータモデルの構造を説明します。
collection/rkey
polkaのすべてのデータは、collection/rkey という形式のパスで管理されます。このパスを rpathと呼びます。
collection
データの種類を示す名前空間です。たとえば、polka.profile はプロフィールデータ、polka.post は投稿データを示します。
rkey
collection内でレコードを一意に識別するidです。TIDが使われます。TIDは、タイムスタンプをベースにした識別子で、作成順にソートされます。
標準collection
polkaで使用される主なcollectionを説明します。
polka.profile/self
ユーザーのプロフィール情報を格納します。rpathは常に polka.profile/self で固定されています。
含まれるフィールド:
name: 表示名description: プロフィールの説明icon: アイコンのURLbanner(オプション): バナー画像のURLupdatedAt: 最終更新日時
polka.post/
投稿データを格納します。rkeyにはTIDが使われます。
含まれるフィールド:
content: 投稿の本文(Markdown形式)parents: この投稿が属するタグの配列updatedAt: 最終更新日時
parents フィールドにタグを指定することで、投稿がどのタグに属するかを示します。複数のタグに同時に属することも可能です。
polka.edge/
タグの階層構造を定義します。polka.edge レコードは、あるタグから別のタグへのエッジを表します。
含まれるフィールド:
from(オプション): 親タグ (省略時はルート)to: 子タグupdatedAt: 最終更新日時
たとえば、japan タグの下に kokeshi タグを作る場合、from: "japan", to: "kokeshi" というedgeレコードを作成します。
from を省略すると、ルート直下のタグとして扱われます。
polka.link/
他のユーザーの投稿やデータへのリンクを表します。
含まれるフィールド:
ref: 参照先(didとrpathを含むオブジェクト)parents: このリンクが属するタグの配列updatedAt: 最終更新日時
たとえば、Aliceさんの投稿を自分のタグに追加したい場合、その投稿へのrefを含むlinkレコードを作成します。
polka.follow/
フォローしているユーザーのタグを記録します。
含まれるフィールド:
did: フォロー対象のDIDtag: フォローしているタグupdatedAt: 最終更新日時
たとえば、did:web:alice.example.com の japan/kokeshi タグをフォローする場合、did: "did:web:alice.example.com", tag: "japan/kokeshi" というfollowレコードを作成します。
アイデンティティと検証
did:webによる紐付け
polkaは、ドメイン名と公開鍵を紐付ける仕組みとして、did:webを採用しています。
did:webとは
did:webは、W3Cが標準化したDecentralized Identifierの一種で、Webドメインを使ったDIDです。
did:web:example.com というDIDは、https://example.com/.well-known/did.json にあるDID Documentを指します。
DID Documentには、そのDIDに紐づく公開鍵とサービスエンドポイントが記載されています。
DID Documentの構造
DID Documentは、JSON形式で記述されます。polkaで使用される典型的なDID Documentは以下のような構造を持ちます。
verificationMethod
公開鍵のリストです。各公開鍵には一意のIDが付けられます。
assertionMethod
署名検証に使用する鍵のリストです。verificationMethod で定義された鍵のIDを参照します。
service
polkaリポジトリのサービスエンドポイントです。クライアントは、このエンドポイントからデータブロックを取得します。
idは#polkaである必要があります。(例:did:web:example.com#polka)
複数鍵対応の仕組み
polkaは、複数の公開鍵をサポートしています。
なぜ複数鍵が必要か
鍵のローテーション 秘密鍵が漏洩した可能性がある場合、新しい鍵に切り替える必要があります。複数鍵に対応していれば、古い鍵を無効化しながら新しい鍵を追加できます。
複数デバイスでの運用 デスクトップとモバイルで異なる鍵を使いたい場合、それぞれの鍵をDID Documentに登録できます。
検証の仕組み
クライアントがデータを検証する際、assertionMethod に含まれるいずれかの鍵で署名が検証できれば、そのデータを正当なものとして受け入れます。
すべての鍵で検証する必要はありません。1つでも検証に成功すれば十分です。
DID解決の流れ
polkaでのDID解決は、以下の手順で行われます。
1. DID DocumentのURL構築
did:web:example.com というDIDから、https://example.com/.well-known/did.json というURLを構築します。
2. HTTPS経由で取得 構築したURLに HTTPSリクエストを送り、DID Documentを取得します。
3. 公開鍵の抽出
verificationMethod から公開鍵を抽出し、assertionMethod で参照されている鍵のリストを得ます。
4. サービスエンドポイントの抽出
service から、polkaリポジトリのサービスエンドポイントを抽出します。idが #polka のサービスを探します。
5. データ取得と検証 サービスエンドポイントからデータを取得し、抽出した公開鍵で署名を検証します。
ネットワークとユーザー発見
polkaのネットワークは、タグを中心とした階層構造と、Nostrによる発見メカニズムで構成されています。
タグによるグラフ構造
polkaでは、ユーザーごとに独自のタグ階層を持ちます。タグは、投稿やリンクを分類するためのカテゴリであり、同時にユーザー間のつながりを形成する単位でもあります。
タグ階層の例
タグはディレクトリのような階層構造を持ちます。
alice.example.com/
└─ japan/
├─ kokeshi/
│ └─ [投稿1, 投稿2, ...]
└─ shinobu/
└─ [投稿3, 投稿4, ...]
└─ photo/
└─ landscape/
└─ [投稿5, 投稿6, ...]
shino.example.com/
└─ kinpatsu/
├─ alice/
│ └─ [投稿7, 投稿8, ...]
└─ karen/
└─ [投稿9, 投稿10, ...]
polka.edgeレコードによる階層定義
タグの階層は、polka.edge レコードで定義されます。
たとえば、Aliceさんが japan の下に kokeshi タグを作る場合、以下のようなedgeレコードを作成します:
rpath: polka.edge/{rkey}
data: {
from: "japan",
to: "kokeshi",
updatedAt: "2025-01-15T10:00:00Z"
}
from フィールドで親タグ、to フィールドで子タグを指定します。from を省略すると、ルート直下のタグとして扱われます。
グラフの再帰的構築
クライアントは、polka.edge レコードを走査することで、タグのグラフ構造を再帰的に構築します。
たとえば、japan タグから始めて、from: "japan" を持つすべてのedgeレコードを取得すれば、その子タグが得られます。
さらに、それらの子タグを from として持つedgeレコードを取得すれば、孫タグが得られます。このように再帰的に辿ることで、タグの階層全体が構築されます。
フォロー機構
polkaでは、特定のユーザーの特定のタグノードをフォローします。
タグノードのフォロー
たとえば、Aliceさんの japan/kokeshi タグに興味がある場合、以下のようなフォローレコードを作成します:
rpath: polka.follow/{rkey}
data: {
did: "did:web:alice.com",
tag: "japan/kokeshi",
updatedAt: "2025-01-15T10:00:00Z"
}
クライアントは、このフォローレコードに基づいて、定期的に Alice さんのリポジトリから japan/kokeshi に属する投稿を取得します。
階層的な購読
タグの階層性により、柔軟な購読が可能です。
特定のカテゴリのみ
alice.com/japan/kokeshi をフォローすれば、そのタグに属する投稿だけが取得されます。
広範囲な購読
alice.com/japan をフォローすれば、その配下の kokeshi、shinobu など、すべてのサブタグの投稿が取得されます。
この柔軟性により、細かい興味に絞ることも、広いトピック全体を網羅することも可能になります。
投稿とタグの関係
投稿は、parents フィールドでタグを指定します。
Nostrによるユーザー発見
polkaは、ユーザー発見にNostrリレーを活用します。
Nostrの役割: 一時的なブートストラップ
重要なのは、Nostrは「発見」のためだけに使われるということです。
ユーザーは自分の存在をNostrリレーに広告し、興味のあるタグを持つ他のユーザーを見つけます。一度つながりを見つけたら、その情報はローカルに保存され、以降はHTTPS経由で直接データを取得します。
Nostrリレーがダウンしても、既存のフォロー関係は影響を受けません。新しいユーザーの発見ができなくなるだけです。
タグ広告 (Kind 25565)
ユーザーは、Nostrリレーに Kind 25565 のイベントを送信します。このイベントには、自分のDIDと、使っているタグのBloom Filterが含まれます。
| フィールド | 内容 |
|---|---|
| kind | 25565 |
| content.did | ユーザーの did:web |
| content.bloom | タグ配列を格納した Bloom Filter(base64エンコード) |
Bloom Filterを使うことで、タグのリストを圧縮表現できます。また、完全なタグリストを公開せずに済むため、プライバシーも保護されます。
発見からフォローまでの流れ
1. クライアントがNostrリレーをsubscribe Kind 25565のイベントを購読します。
2. イベントを受信 他のユーザーが送信したタグ広告イベントを受け取ります。
3. Bloom Filterでマッチングチェック 受信したBloom Filterに対して、自分が興味のあるタグが含まれているかをチェックします。マッチしたら次のステップに進みます。
4. did:web解決 イベントに含まれるDIDを解決し、公開鍵とサービスエンドポイントを取得します。
5. データ取得と確認 サービスエンドポイントからデータを取得し、実際にそのタグが存在するかを確認します。(Bloom Filterは偽陽性の可能性があるため)
6. フォローレコードを作成
確認が取れたら、polka.follow レコードを作成し、定期的にそのユーザーのデータを取得するようにします。
以降、Nostrリレーを経由せず、HTTPS経由で直接データを取得し続けます。
コミュニティの自然発生
polkaのタグは、中央管理者がいません。誰でも好きなタグを作り、使うことができます。
共通のタグによるつながり
たとえば、kokeshi というタグを使う人々が増えれば、自然とkokeshiコミュニティが形成されます。
Aliceさんが japan/kokeshi を使い、Bobさんが hobby/kokeshi を使い、Carolさんが collection/kokeshi を使えば、3人とも kokeshi に興味がある人として発見され、つながることができます。
タグの自由度
タグに厳密なルールはありません。階層の深さも、名前の付け方も、ユーザーの自由です。
この自由度により、それぞれのユーザーが自分の感覚でタグを付けることで、自然と分類が育まれます。
Nostr使用の一時性
繰り返しになりますが、polkaにおけるNostrの使用は一時的です。
初期発見のみ Nostrは新しいユーザーを発見するときだけ使われます。
継続的なデータ取得はHTTPS 一度フォローしたユーザーのデータは、HTTPS経由で直接取得します。Nostrリレーは経由しません。
リレーダウンの影響は限定的 Nostrリレーがダウンしても、既存のフォロー関係でデータを取得し続けることができます。新規のユーザー発見だけができなくなります。
この設計により、polkaは大規模なリレーインフラに依存せず、最小限の調整でネットワークが機能します。