ネットワークとユーザー発見
polkaのネットワークは、タグを中心とした階層構造と、Nostrによる発見メカニズムで構成されています。
タグによるグラフ構造
polkaでは、ユーザーごとに独自のタグ階層を持ちます。タグは、投稿やリンクを分類するためのカテゴリであり、同時にユーザー間のつながりを形成する単位でもあります。
タグ階層の例
タグはディレクトリのような階層構造を持ちます。
alice.example.com/
└─ japan/
├─ kokeshi/
│ └─ [投稿1, 投稿2, ...]
└─ shinobu/
└─ [投稿3, 投稿4, ...]
└─ photo/
└─ landscape/
└─ [投稿5, 投稿6, ...]
shino.example.com/
└─ kinpatsu/
├─ alice/
│ └─ [投稿7, 投稿8, ...]
└─ karen/
└─ [投稿9, 投稿10, ...]
polka.edgeレコードによる階層定義
タグの階層は、polka.edge レコードで定義されます。
たとえば、Aliceさんが japan の下に kokeshi タグを作る場合、以下のようなedgeレコードを作成します:
rpath: polka.edge/{rkey}
data: {
from: "japan",
to: "kokeshi",
updatedAt: "2025-01-15T10:00:00Z"
}
from フィールドで親タグ、to フィールドで子タグを指定します。from を省略すると、ルート直下のタグとして扱われます。
グラフの再帰的構築
クライアントは、polka.edge レコードを走査することで、タグのグラフ構造を再帰的に構築します。
たとえば、japan タグから始めて、from: "japan" を持つすべてのedgeレコードを取得すれば、その子タグが得られます。
さらに、それらの子タグを from として持つedgeレコードを取得すれば、孫タグが得られます。このように再帰的に辿ることで、タグの階層全体が構築されます。
フォロー機構
polkaでは、特定のユーザーの特定のタグノードをフォローします。
タグノードのフォロー
たとえば、Aliceさんの japan/kokeshi タグに興味がある場合、以下のようなフォローレコードを作成します:
rpath: polka.follow/{rkey}
data: {
did: "did:web:alice.com",
tag: "japan/kokeshi",
updatedAt: "2025-01-15T10:00:00Z"
}
クライアントは、このフォローレコードに基づいて、定期的に Alice さんのリポジトリから japan/kokeshi に属する投稿を取得します。
階層的な購読
タグの階層性により、柔軟な購読が可能です。
特定のカテゴリのみ
alice.com/japan/kokeshi をフォローすれば、そのタグに属する投稿だけが取得されます。
広範囲な購読
alice.com/japan をフォローすれば、その配下の kokeshi、shinobu など、すべてのサブタグの投稿が取得されます。
この柔軟性により、細かい興味に絞ることも、広いトピック全体を網羅することも可能になります。
投稿とタグの関係
投稿は、parents フィールドでタグを指定します。
Nostrによるユーザー発見
polkaは、ユーザー発見にNostrリレーを活用します。
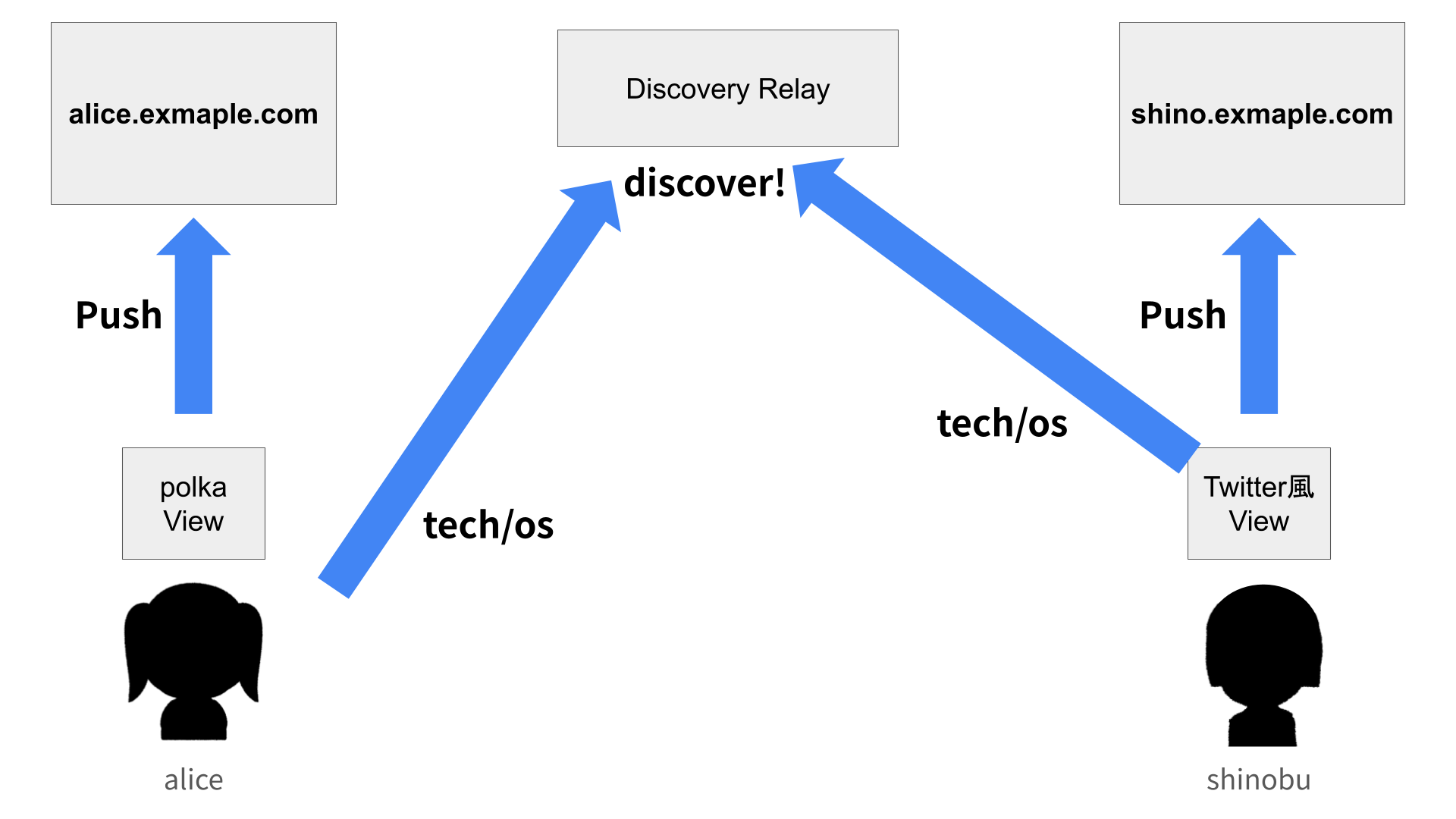
Nostrの役割: 一時的なブートストラップ
重要なのは、Nostrは「発見」のためだけに使われるということです。
ユーザーは自分の存在をNostrリレーに広告し、興味のあるタグを持つ他のユーザーを見つけます。一度つながりを見つけたら、その情報はローカルに保存され、以降はHTTPS経由で直接データを取得します。
Nostrリレーがダウンしても、既存のフォロー関係は影響を受けません。新しいユーザーの発見ができなくなるだけです。
タグ広告 (Kind 25565)
ユーザーは、Nostrリレーに Kind 25565 のイベントを送信します。このイベントには、自分のDIDと、使っているタグのBloom Filterが含まれます。
| フィールド | 内容 |
|---|---|
| kind | 25565 |
| content.did | ユーザーの did:web |
| content.bloom | タグ配列を格納した Bloom Filter(base64エンコード) |
Bloom Filterを使うことで、タグのリストを圧縮表現できます。また、完全なタグリストを公開せずに済むため、プライバシーも保護されます。
発見からフォローまでの流れ
1. クライアントがNostrリレーをsubscribe Kind 25565のイベントを購読します。
2. イベントを受信 他のユーザーが送信したタグ広告イベントを受け取ります。
3. Bloom Filterでマッチングチェック 受信したBloom Filterに対して、自分が興味のあるタグが含まれているかをチェックします。マッチしたら次のステップに進みます。
4. did:web解決 イベントに含まれるDIDを解決し、公開鍵とサービスエンドポイントを取得します。
5. データ取得と確認 サービスエンドポイントからデータを取得し、実際にそのタグが存在するかを確認します。(Bloom Filterは偽陽性の可能性があるため)
6. フォローレコードを作成
確認が取れたら、polka.follow レコードを作成し、定期的にそのユーザーのデータを取得するようにします。
以降、Nostrリレーを経由せず、HTTPS経由で直接データを取得し続けます。
コミュニティの自然発生
polkaのタグは、中央管理者がいません。誰でも好きなタグを作り、使うことができます。
共通のタグによるつながり
たとえば、kokeshi というタグを使う人々が増えれば、自然とkokeshiコミュニティが形成されます。
Aliceさんが japan/kokeshi を使い、Bobさんが hobby/kokeshi を使い、Carolさんが collection/kokeshi を使えば、3人とも kokeshi に興味がある人として発見され、つながることができます。
タグの自由度
タグに厳密なルールはありません。階層の深さも、名前の付け方も、ユーザーの自由です。
この自由度により、それぞれのユーザーが自分の感覚でタグを付けることで、自然と分類が育まれます。
Nostr使用の一時性
繰り返しになりますが、polkaにおけるNostrの使用は一時的です。
初期発見のみ Nostrは新しいユーザーを発見するときだけ使われます。
継続的なデータ取得はHTTPS 一度フォローしたユーザーのデータは、HTTPS経由で直接取得します。Nostrリレーは経由しません。
リレーダウンの影響は限定的 Nostrリレーがダウンしても、既存のフォロー関係でデータを取得し続けることができます。新規のユーザー発見だけができなくなります。
この設計により、polkaは大規模なリレーインフラに依存せず、最小限の調整でネットワークが機能します。